In komplexen Software-Systemen wird ziemlich schnell die Frage aufgeworfen, “Welche Technologie soll für die Kommunikation zwischen Server-Objekten und deren Repräsentanten auf dem Client eingesetzt werden?”. Dabei stehen zahlreiche Möglichkeiten zur Auswahl. Wenn es aber darum geht, eine vollständig transparente Abbildung des Objektbaumes auf dem Client zu realisieren, sodass sich dieser tatsächlich so verhält als würde er auf dem Client beheimatet sein, bleibt die Frage in der Regel unbeantwortet. Es werden dann Technologien eingesetzt, die annähernd die Anforderungen decken, der Rest wird durch entsprechende Intelligenz in der Anbindung realisiert. Allerdings sind diese Lösungen dann für den Anwendungsfall spezifisch. Seit kurzem schickt sich ein neues Framework an, genau diese Lücke zu schließen: Remote Method Call.
Hintergrund
Das EU-Forschungsprojekt OpenNode [2], beschäftigt sich im Themengebiet Smart Grid, mit der letzten Meile im Energienetz. Genauer gesagt mit neuen Konzepten zur Automatisierung der Transformatorenhäuschen, den so genannten Secondary Substations, welche die Haushalte direkt mit Strom beliefern. Sie dienen dazu, die Energie, die zur Übertragung über lange Strecken auf eine, für diesen Zweck effizientere Spannung hochtransformiert wurde, wieder auf 230 Volt herunter zu transformieren und den Verbrauchern ausfallsicher zur Verfügung zu stellen. Dazu dienen im Wesentlichen mehrere Transformatoren und Elektronik zur Überwachung und Lastverteilung. Künftig sollen diese Stationen an die Energieversorger angeschlossen werden, sodass diese direkt mit ihnen Daten austauschen und kontrollierend einwirken können. Weiterhin werden die Secondary Substations als Datensammler für Energiedaten der Haushalte ausgebaut, sodass wir langfristig unsere Stromrechnung monatlich, nach dem tatsächlichen Verbrauch bezahlen werden. Dazu kommuniziert das Trafohäuschen mit jedem einzelnen, intelligenten Stromzähler (Smart Meter) der Haushalte, basierend auf Powerline Communication, also Datenaustausch über das Energienetz selbst.
Die Mission
Im Rahmen des Projektes wird ein Prototyp eines Embedded Servers realisiert, der Secondary Substation Node (SSN). Dieser dient als Bindeglied zwischen den Supervisory Control and Data Acquisition (SCADA) [3] Systemen der Energieversorger, den Geräten und Anlagen innerhalb des Trafohäuschens, sowie den einzelnen Stromzählern der Haushalte. Dazu finden vielfältige Kommunikationstechnologien ihre Anwendung, wie IEC60870-104 [4] zur Anbindung der SCADA Systeme und der Automatisierungstechnik, DLMS/COSEM [5] als Datenträger der Energiedaten der Smart Meter, PRIME [6] als Powerline basiertes Kommunikationsprotokoll, uvam.
Man hat sich sehr früh im Projekt entschieden, weitestgehend offene Technologien, sowohl für das Betriebssystem (Ubuntu Server), als auch zur Entwicklung der Software (Java, OSGi, Web-Services), zu verwenden.
Der Server hält permanent eine Repräsentation der Prozessdaten als IEC61850 [7] basiertes Datenmodell für den Zugriff durch Applikationen auf dem SSN, die Mess-, Steuer- und Regelungsaufgaben wahrnehmen und für die entfernten SCADA Systeme, welche die Prozesshoheit besitzen, bereit.
Zur einfachen Visualisierung der aktuellen Prozessdaten und für Diagnosezwecke während der Entwicklung, sollte ein “kleines” Werkzeug realisiert werden, das den direkten Einblick in das IEC61850 basierte Java Objektmodell auf dem SSN, mit der Möglichkeit, Messwerte grafisch darzustellen, erlaubt. Die Software auf dem SSN besteht dabei aus einer Vielzahl OSGi-Bundels, die in einer Equinox [8] Laufzeitumgebung betrieben werden.
Ziel war es möglichst die gleiche Repräsentation des Objektmodells innerhalb des Werkzeuges zu verwenden, wie sie auf dem Server zu finden ist. Dadurch wird nicht zu letzt die Austauschbarkeit der Kommunikationsanbindung an das Datenmodell gewährleistet. Mal wird das Modell auf dem Client betrieben, mal soll via Netzwerk auf das Modell des SSN zugegriffen werden.
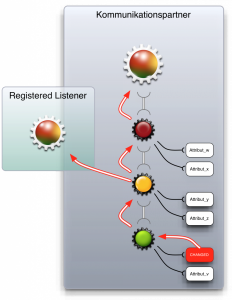
Abb. 1 – Benachrichtigung in der Objekthirarchie
Das Objektmodell ist in Abbildung 1 skizziert. Es besteht aus einzelnen Knoten, die in einer Eltern-Kind-Beziehung stehen. Andere Knoten erlaubt es, Listener zu registrieren, die über Veränderungen an dem Objekt oder einem seiner Kinder informieren. Das bedeutet: Wird ein Knoten modifiziert, meldet er dies seinem Eltern-Knoten und allen Listenern, die auf diesem Knoten registriert sind. Der Eltern-Knoten meldet das Ereignis wiederum seinem Eltern-Knoten und allen Listenern, die auf ihm registriert sind. Der Vorgang wird so lange fortgeführt, bis das Ereignis am obersten Eltern-Knoten angekommen ist. Damit haben Anwendungen die Möglichkeit, auf dedizierten Knoten – oder irgendwo in der Hierarchie darüber – zu horchen, um so über Änderungen an untergeordneten Knoten informiert zu werden.
Das Problem
Es galt nun, dieses Modell auf dem SSN via Netzwerk auf einem Client in dem Visualisierungswerkzeug zu nutzen und das möglichst so, dass es sich genauso wie auf dem Server verhält. Selbstverständlich denkt man bei einem objektbasierten Zugriff auf entfernte Objekte an Remote Method Invocation (RMI) [9].
Es hat sich aber schnell herausgestellt, dass RMI den Herausforderungen bei weitem nicht gewachsen war. Es ist zwar prinzipiell einfach zu verwenden, man kann relativ schnell entfernte Objekte anbinden, hat aber eine Reihe von Nachteilen, die es unmöglich machen, ein Objektmodell, wie es beschrieben wurde, wirklich völlig transparent anzubinden.
Es genügt nicht, einen Methodenaufruf an das entfernte Objekt zu delegieren und das Ergebnis wieder zum Client zurück zu senden. Ferner müssen Events, die durch Änderung bei einem der Teilnehmer hervorgerufen wurden ebenfalls bei allen anderen Teilnehmern propagiert werden. D.h. jeder der Teilnehmer benötigt potentiell Zugriff auf den anderen.
Konkreter gesagt: Registriert z.B. Der Client einen Listener auf einem Objekt, muss dieser letztendlich auf dem Server-Objekt registriert werden. Wird ein Event gefeuert, wird eben dieser Listener auf dem Server-Objekt benachrichtig. D.h. Diese Methode wird aufgerufen, was zur Folge hat, dass dieser Aufruf zurück zum Client delegiert wird, um den tatsächlichen Listener zu benachrichtigen. Das erfordert also eine bidirektionale Kommunikation zwischen Server-Objekten und deren Repräsentanten auf dem Client.
RMI kann das nicht leisten. Es wird EIN Objekt von der Server-Anwendung bereitgestellt, das mittels eines eindeutigen Namens adressiert wird. Ruft der Client eine Methode auf dem Objekt auf, wird dieser Aufruf via Netzwerk an das Server-Objekt geschickt, ausgeführt und das Ergebnis an den Aufrufer zurückgeleitet. Die eigentlichen Nutzdaten, also Übergabeparameter der Methode und der Return Value, bzw. die Exception, im Falle eines Fehlers, wird mittels Serialisierung [10] in einen Binärstrom codiert und vom Empfänger wieder decodiert. Damit werden diese Objekte kopiert. Es besteht keine Verbindung mehr zu dem ursprünglichen Objekt.
Ein zweiter wesentlicher Aspekt bei RMI ist, dass Methodenaufrufe ausschließlich an Server-Objekte gerichtet werden können. Damit der Server eine Method, z.B. bei den genannten Listenern, aufrufen kann, müssen die Listener via RMI zur Verfügung gestellt werden. der Server muss diese dann explizit Adressieren um eine Verbindung zu den Listenern herstellen zu können. Es muss zusätzliche Intelligenz in Client und Server implementiert werden, damit man annähernd das genannte Verhalten realisieren kann.
Der dritte essentielle Haken an RMI ist, dass mit einer Verbindung immer nur ein einziges Objekt für entfernte Zugriffe zur Verfügung steht. Will man also auf jedem Objekt in einen Objektbaum mit mehreren tausend Objekten entfernte Methoden aufrufen, benötigt man ebenso viele Verbindung zu den Server-Objekten und bei RMI nochmal genauso viele Namen, um diese Objekte überhaupt ansprechen zu können. Bei einer bidirektionalen Kommunikation müssen dann nochmal Verbindungen mit der gleichen Anzahl in der anderen Richtung verwaltet werden. Bei einem Objektmodell mit über 3000 Knoten, wie es aktuell bei dem SSN vorliegt, würden über 6000 Verbindungen auf Client und Server benötigt.
Die Lösung
Wir bei brainchild haben nicht lang Überlegt und ein OpenSource-Projekt daraus gemacht, das wir mit eigenen Mitteln realisieren, um diese Lücke zu schließen und eine frei zugängliche Lösung anzubieten: Remote Method Call [11].
Der Name Remote Method Call geht auf eine Entwicklung von Adam Bien von vor über einem Jahrzehnt zurück. Er hatte damals im Java Magazin über die damaligen Probleme von RMI – man musste damals z.B. noch den RMI Compiler bemühen, um den Kommunikations-Code zu generieren – berichtet und eine passende Lösung präsentiert. Allerdings war das damalige RMC funktional identisch zum Sun RMI.
Was ist nun an unserem RMC anders?
- Man kann mit nur zwei Zeilen Code auf Client und Server eine Verbindung zwischen zwei Objekten herstellen.
- Es erweitert die Konventionen von RMI
- Objekte bzw. Interfaces, die für Remote-Zugriffe zur Verfügung stehen sollen, müssen entweder java.rmi.Remote implementieren oder mit der Annotation de.brainchild.rmc.Remote versehen sein.
- Alle Objekte, die übertragen werden, also Parameter und Rückgabewerte, müssen serialisierbar sein, siehe [10].
- Methoden können explizit vom Remote-Zugriff ausgenommen werden, entweder indem sie mit der Annotation de.brainchild.Local markiert werden, oder in dem man diese Methoden in einer Komma getrennten Liste der System-Property de.brainchild.rmc.executeLocal zuweist.
- Im Gegensatz zu RMI ist RMC nicht ausschließlich auf die Kommunikation via Sockets beschränkt. Es ist vielmehr völlig unabhängig vom Übertragungsmedium. Es ist sehr einfach andere Kommunikationsmedien, wie z.B. Busse oder serielle Medien anzubinden. Dazu muss nur eine Klasse vom Typ de.brainchild.rmc.ConnectionFactory bereit gestellt werden.
- In einem RMC Kommunikationsszenarium gibt es einen Server und beliebig viele Clients. Der Server exportiert das zentrale Objekt, z.B. Eine Factory, um an das Datenmodell zu gelangen, bzw. das Datenmodell selbst – was genau, ist anwendungsspezifisch. Der Client bindet das entsprechende Interface an das Server-Objekt.
Und wie funktioniert RMC?
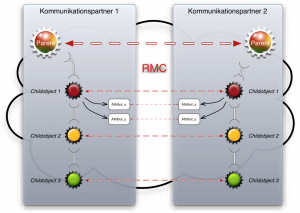
Abb. 2 – Kommunikation zwischen lokalem- und Remote- Objektbaum via RMC
Abbildung 2 skizziert den Aufbau von RMC. Jedes entfernte Objekt wird vom RMC-Framework mit einer Hülle versehen, dem de.brainchild.rmc.RemoteObject. Diese Hülle ist verantwortlich für das Delegieren entfernter Aufrufe und bedient sich dabei einer de.brainchild.Connection, die mittels der de.brainchild.rmc.ConnectionFactory erzeugt wird. Außerdem nimmt diese Hülle auch die Methodenaufrufe entgegen, führt sie auf dem entsprechenden Zielobjekt aus und sendet das Ergebnis, Rückgabewerte oder Exception, zurück an den Aufrufer. Werden nun Parameter oder Rückgabewerte übertragen, die ebenfalls als java.rmi.Remote, bzw. de.brainchild.rmc.Remote, gekennzeichnet sind, registriert das empfangende RemoteObject sie als solche und dekoriert sie ebenfalls als RemoteObject. Damit stehen sie wiederum für entfernte Aufrufe zur Verfügung. Dem eigentlichen, empfangenden Zielobjekt, z.B. beim Registrieren eines Listeners, wird das stellvertretende RemoteObject übergeben. Ruft dieses nun eine Methode auf dem Objekt auf, wie z.B. die des Listeners, wird der Aufruf an das Zielobjekt übertragen, womit das “Spiel” von vorn beginnt. Die ganze Magie im Hintergrund der Hülle wird mittels Dynamic Proxies [12] realisiert.
Referenzen
[1] https://brain-child.de
[2] https://www.opennode.eu
[3] https://de.wikipedia.org/wiki/Supervisory_Control_and_Data_Acquisition
[4] https://de.wikipedia.org/wiki/IEC_60870
[5] https://www.dlms.com
[6] https://www.iberdrola.es/webibd/corporativa/iberdrola?IDPAG=ENWEBPROVEEBASDOCCONT
[7] https://de.wikipedia.org/wiki/IEC_61850
[8] https://www.eclipse.org/equinox
[9] https://www.oracle.com/technetwork/java/javase/tech/index-jsp-136424.html
[10] https://download.oracle.com/javase/7/docs/technotes/guides/serialization/index.html
[11] https://sourceforge.net/p/jrmc/home/Home/
[12] https://download.oracle.com/javase/7/docs/technotes/guides/reflection/proxy.html


 Die G1000® All-Glass Avionics Suite aus dem Hause Garmin® erfreut sich nicht nur im Bereich Business Aviation großer Beliebtheit, sondern auch zunehmend in der privaten Fliegerei. Der Grund dafür liegt zweifelsfrei an dem großen Funktionsumfang, der nicht nur ungeahnten Komfort, sondern auch Sicherheit in das Cockpit bringt. Dies kommt allerdings zum Preis eines komplexen Systems, das einer eingehenden Schulung bedarf.
Die G1000® All-Glass Avionics Suite aus dem Hause Garmin® erfreut sich nicht nur im Bereich Business Aviation großer Beliebtheit, sondern auch zunehmend in der privaten Fliegerei. Der Grund dafür liegt zweifelsfrei an dem großen Funktionsumfang, der nicht nur ungeahnten Komfort, sondern auch Sicherheit in das Cockpit bringt. Dies kommt allerdings zum Preis eines komplexen Systems, das einer eingehenden Schulung bedarf.